404 : Python Bases - Fichiers csv
Préparation des données
< EDIT COURS A DISTANCE>
SOYEZ TRES ATTENTIFS A LA PREPARATION DES DONNEES : si les ressources fournies ne se trouvent exactement comme je vous le demande, rien ne fonctionnera.
De plus, comme je ne peux pas répondre de manière aussi interactive qu'en cours, il vous appartient de rechercher par vous même des informations complémentaires que je ne donne pas ici pour ne pas alourdir la rédaction des TP, soyez donc curieux.
</EDIT>

Avec votre dossier ressource 0800 : 0800 : ressources Application aux bases de données[1]
Ouvrir avec le tableur les fichiers table*.ods un par un avec excel ou libreoffice calc
Ouvrir avec un éditeur de texte (bloc notes ou notepad ++) les fichiers tb*.csv
Le format ods peut être exploité dans un langage de programmation, mais les données qu'il contient peuvent changer d'une version de Libreoffice à une autre, le format CSV ne changera jamais même si les données texte qu'il contient peuvent être présentées différemment.
Avec le site serveur python anywhere :
Ajouter un dossier app (il existe peut-être déjà)
Ajouter un dossier notes dans le dossier app
Charger (upload) les fichiers nommé tb_*.csv dans le dossier (app/notes)
Les fichiers .py que vous allez télécharger sont documentés : lisez les commentaires
Télécharger le module de fonctions utiles : csvmod.py[2]. Ce fichier ne doit pas être modifié : il va fournir des fonctions de lecture afin que vous puissiez les réutiliser facilement dans votre code.
Télécharger le fichier : csv-tb_Bases.py[3]. A chaque nouvelle étape, vous dupliquerez ce fichier afin de le compléter avec le code que je propose de manière dirigée ou le code que vous devrez ajouter selon les besoins de l'exercice.
Ce programme de base a absolument besoin du fichier csvmod.py pour s'exécuter correctement
EXEMPLE --> Travailler avec des fichiers CSV - Données de fiabilité
Dans le dossier 0800, ouvrir le fichier src_9_1.csv avec un éditeur de texte.
Uploader ce fichier dans votre espaces pythonanywhere (cela veut dire que fichier doit être présent dans votre espace dit <distant>
Télécharger le fichier csv_lit_fiab_src_9_1_1.py[4] et uploader le dans votre espace perso dans python anywhere
Lire les remarques documentaires du dépôt gist --> cela vous donnes les informations nécessaires aux règles de codage des données que je me suis imposé pour que les traitements puissent accéder aux données contenues dans le fichier csv.
En exécutant ce code, vous pouvez comparer le contenu du fichier src_9_1.csv avec l'affichage obtenu avec le programme python.
Calculer la moyenne par matière
Nous allons partir du fichier tb_mat.csv et ajouter une colonne moyenne par matière dans un nouveau fichier csv.
Ainsi, en chargeant ce nouveau fichier sous un tableur, nous pourrons visualiser les moyennes par matière.
Les questions ci-dessous sont les étapes visant à décomposer ce traitement.
Etape 1 : lire les notes et calculer la moyenne générale.
Ouvrir le fichier csv-tb_Bases.py, puis le sauvegarder avec le nom csv-moygen.py
Pour calculer la moyenne générale des notes sans tenir compte de la matière à laquelle elles sont affectées, nous avons donc besoin uniquement des notes qui sont stockées dans le fichier tb_note.csv.
Pour cela, le code ci-dessous pour stocker les données des matières (fichier tb_note.csv) dans des listes (extrait de csv-tb-Bases.py) suffira. Pas besoin de lire les 2 autres fichiers csv, puisque on n'a pas besoin de l'étudiant ou de la matière concernés par la note.
from csvmod import * # import des fonctions du module csvmod.py
tbAtt_note = []
id_note = []
id_note_et = []
id_note_mat = []
note = [] # initialisation de la liste note
tbAtt_note = fLit_note(id_note,id_note_et,id_note_mat,note) # fonction de lecture du fichier tb_note.csv
print (tbAtt_note,id_note,id_note_et,id_note_mat,note) # pour vérifier la bonne extraction des données
Comme nous utilisons la fonction fLitnote qui à été conçue pour récupérer toutes les colonnes du fichier tb_note.csv, nous sommes forcés d'utiliser les listes id_note, tbAtt_note, id_note_et et id_note_mat.
Mais seule la liste note est utile pour calculer la moyenne générale sans tenir compte des coefficients affectés aux matières.
A ce titre, une fonction python peut gérer des paramètres optionnels : on pourrait modifier la fonction pour demander à cette fonction de ne retourner que la liste des notes : cela rendrait le code plus léger.
Question
Calculer la moyenne des notes (déjà vu dans l'exercice 403) en :
utilisant la fonction sum(liste)
ou en utlisant une boucle for avec une variable cumul qui effectue la somme de toutes les notes
Solution
Solution avec sum
# Ce calcul ne tient pas compte des coefficients associés aux matièresMoyenneGen = sum(note)/len(note)
print(MoyenneGen)
Solution avec la boucle
somNotes = 0 # initialisation à 0 de la variable cumul
for note in notes:
# addition à chaque itération de chaque note à la variable cumul somNotes +=note # même chose que somNotes = somNotes + note
print(somNotes) # la somme est affichée après chaque note cumulée
moyenne = somNotes / nb
print(moyenne)
Etape 2 : extraire des éléments d'une liste et en calculer la moyenne
L'objectif est de générer une liste de notes pour chaque matière et pour chaque liste obtenue et d'en calculer la moyenne (ce que l'on sait faire à l'étape 1)
Ouvrir le fichier csv-tb_Bases.py, puis le sauvegarder avec le nom csv-mat-moy.py
Chaque note est affectée à une matière qui est identifiée avec son attribut id_mat
Test préalable : Créer une liste composée des notes de la matière dont l'identifiant id_note_mat est égal à 1. Le code ci-dessous contient un exemple de création d'une liste en ajoutant les éléments d'une liste de base avec la condition : l'élément fait parti de la nouvelle liste si l'élément est supérieur à 5.
a = [1,4,2,7,1,9,0,3,4,6,6,6,8,3]
b = []
for x in a:
if x > 5:
b.append(x)
print(b)
Ce qui donnera [7, 9, 6, 6, 6, 8] dans la nouvelle liste
Question
Créer une liste nommée notemat1 composée des notes de la matière ayant comme identifiant id_note_mat = 1
Solution
notemat1 = []
for index in range(0,len(note)):
if id_note_mat [index] == 1 :
notemat1.append(note[index])
print (notemat1)
Question
Calculer la moyenne des notes de la matière id_note_mat = 1
Solution
notemat1 = []
for index in range(0,len(note)):
if id_note_mat [index] == 1 :
notemat1.append(note[index])
moymat1 = sum(notemat1)/len(notemat1)
print (moymat1)
Question
Peut-on simplifier le code et cumuler seulement les notes de la matière dont id_note_mat est égal à 1 sans utiliser une liste ?
Solution
sumN = 0
nbN = 0
for inote in range(0,len(note)):
if id_note_mat [inote] == 1 :
sumN +=note[inote]
nbN +=1
moymat = sumN/nbN
Etape 3 : calcul de la moyenne de toutes les matières -> généralisation des solution précédentes.
Maintenant que l'on sait calculer la moyenne des notes d'une matière, il faudrait calculer la moyenne de toutes les matières sans dupliquer le code en changeant les variables notemat1 en notemat2, etc
Pour faire simple, sans chercher à optimiser le code, on peut faire une boucle indéxée sur la liste des matières qui va imbriquer la boucle indéxée sur la liste des notes.
Question
Il suffit alors d'utiliser une liste moymat pour stocker la variable moymat de chaque matière.
Attention à lire les fihiers tb_mat.csv et tb_note.csv. Il faut donc réinjecter le code de lecture des 2 fichiers à partir du programme : csv-tb_Bases.py[5].
Solution
moymat = []
for imat in range(0,len(id_mat)):
sumN = 0
nbN = 0
for inote in range(0,len(note)):
if id_note_mat [inote] == id_mat[imat] :
sumN +=note[inote]
nbN +=1
moymat.append(sumN/nbN)
Ecriture du fichier tb_mat_moy.csv
A la fin de ce traitement, il faut obtenir ce contenu de fichier :
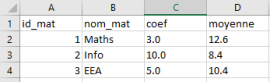
Lors de la lecture des fichiers, les données sont lues lignes par lignes et le traitement des lignes avait pour objectif de créer des listes pour chaque colonne : les colonnes sont des attributs
De même, pour l'écriture, il faut préparer les lignes à écrire dans le fichier : il serait donc pertinent de conserver dès la lecture les données lignes par lignes dans une structure qui serait une liste de lignes : les lignes sont des tuples.
La première ligne (entête ou liste d'attributs) est conservée dans la liste nommée tbAtt_mat
Il faut ajouter à cette liste le titre de la colonne moyenne avec : tbAtt_mat.append('moyenne')
Pour chaque matière il faut donc générer la liste des valeurs (tuple) composée des données dont disposons avec les listes de chaque attribut : id_mat, nom_mat, coef_mat et moymat que nous avons calculé ci-dessus.
Question
Analyser le code ci-dessous et essayer d'en déduire l'instruction permettant d'écrire la ligne d'entête
with open(fnom, "w", newline='') as f:
# création de l'objet ecriture en respectant le dialecte excel-fr ecriture = csv.writer(f,'excel-fr')
# lignes à écrire avec ecriture.writerow(STRUCTURE LISTE DES ELEMENTS DE CHAQUE COLONNES) f.close()
Solution
tbAtt_mat.append('moyenne')
fnom="tb_mat_moy.csv"
with open(fnom, "w", newline='') as f:
ecriture = csv.writer(f,'excel-fr')
# la première ligne à écrire est dans la liste tbAtt_matecriture.writerow(tbAtt_mat)
# boucle sur les matières (3 itérations donc)f.close()
Tester ce code et visualiser le contenu du fichier obtenu
Question
Analyser le code corrigé ci-dessus qui écrit dans le fichier la première ligne du fichier : à savoir la ligne d'entête représentée par la structure de données liste nommée tb_Att_mat.
Solution
tbAtt_mat.append('moyenne')
fnom="tb_mat_moy.csv"
with open(fnom, "w", newline='') as f:
ecriture = csv.writer(f,'excel-fr')
# la première ligne à écrire est dans la liste tbAtt_matecriture.writerow(tbAtt_mat)
for i in range(0,len(id_mat)):
lig = []
lig.append(id_mat[i])
lig.append(nom_mat[i])
lig.append(coef_mat[i])
lig.append(moymat[i])
ecriture.writerow(lig)
f.close()